Our websites may use cookies to personalize and enhance your experience. By continuing without changing your cookie settings, you agree to this collection. For more information, please see our University Websites Privacy Notice .
Neag School of Education

Educational Research Basics by Del Siegle
Experimental research.
The major feature that distinguishes experimental research from other types of research is that the researcher manipulates the independent variable. There are a number of experimental group designs in experimental research. Some of these qualify as experimental research, others do not.
- In true experimental research , the researcher not only manipulates the independent variable, he or she also randomly assigned individuals to the various treatment categories (i.e., control and treatment).
- In quasi experimental research , the researcher does not randomly assign subjects to treatment and control groups. In other words, the treatment is not distributed among participants randomly. In some cases, a researcher may randomly assigns one whole group to treatment and one whole group to control. In this case, quasi-experimental research involves using intact groups in an experiment, rather than assigning individuals at random to research conditions. (some researchers define this latter situation differently. For our course, we will allow this definition).
- In causal comparative ( ex post facto ) research, the groups are already formed. It does not meet the standards of an experiment because the independent variable in not manipulated.
The statistics by themselves have no meaning. They only take on meaning within the design of your study. If we just examine stats, bread can be deadly . The term validity is used three ways in research…
- I n the sampling unit, we learn about external validity (generalizability).
- I n the survey unit, we learn about instrument validity .
- In this unit, we learn about internal validity and external validity . Internal validity means that the differences that we were found between groups on the dependent variable in an experiment were directly related to what the researcher did to the independent variable, and not due to some other unintended variable (confounding variable). Simply stated, the question addressed by internal validity is “Was the study done well?” Once the researcher is satisfied that the study was done well and the independent variable caused the dependent variable (internal validity), then the research examines external validity (under what conditions [ecological] and with whom [population] can these results be replicated [Will I get the same results with a different group of people or under different circumstances?]). If a study is not internally valid, then considering external validity is a moot point (If the independent did not cause the dependent, then there is no point in applying the results [generalizing the results] to other situations.). Interestingly, as one tightens a study to control for treats to internal validity, one decreases the generalizability of the study (to whom and under what conditions one can generalize the results).
There are several common threats to internal validity in experimental research. They are described in our text. I have review each below (this material is also included in the PowerPoint Presentation on Experimental Research for this unit):
- Subject Characteristics (Selection Bias/Differential Selection) — The groups may have been different from the start. If you were testing instructional strategies to improve reading and one group enjoyed reading more than the other group, they may improve more in their reading because they enjoy it, rather than the instructional strategy you used.
- Loss of Subjects ( Mortality ) — All of the high or low scoring subject may have dropped out or were missing from one of the groups. If we collected posttest data on a day when the honor society was on field trip at the treatment school, the mean for the treatment group would probably be much lower than it really should have been.
- Location — Perhaps one group was at a disadvantage because of their location. The city may have been demolishing a building next to one of the schools in our study and there are constant distractions which interferes with our treatment.
- Instrumentation Instrument Decay — The testing instruments may not be scores similarly. Perhaps the person grading the posttest is fatigued and pays less attention to the last set of papers reviewed. It may be that those papers are from one of our groups and will received different scores than the earlier group’s papers
- Data Collector Characteristics — The subjects of one group may react differently to the data collector than the other group. A male interviewing males and females about their attitudes toward a type of math instruction may not receive the same responses from females as a female interviewing females would.
- Data Collector Bias — The person collecting data my favors one group, or some characteristic some subject possess, over another. A principal who favors strict classroom management may rate students’ attention under different teaching conditions with a bias toward one of the teaching conditions.
- Testing — The act of taking a pretest or posttest may influence the results of the experiment. Suppose we were conducting a unit to increase student sensitivity to prejudice. As a pretest we have the control and treatment groups watch Shindler’s List and write a reaction essay. The pretest may have actually increased both groups’ sensitivity and we find that our treatment groups didn’t score any higher on a posttest given later than the control group did. If we hadn’t given the pretest, we might have seen differences in the groups at the end of the study.
- History — Something may happen at one site during our study that influences the results. Perhaps a classmate dies in a car accident at the control site for a study teaching children bike safety. The control group may actually demonstrate more concern about bike safety than the treatment group.
- Maturation –There may be natural changes in the subjects that can account for the changes found in a study. A critical thinking unit may appear more effective if it taught during a time when children are developing abstract reasoning.
- Hawthorne Effect — The subjects may respond differently just because they are being studied. The name comes from a classic study in which researchers were studying the effect of lighting on worker productivity. As the intensity of the factor lights increased, so did the work productivity. One researcher suggested that they reverse the treatment and lower the lights. The productivity of the workers continued to increase. It appears that being observed by the researchers was increasing productivity, not the intensity of the lights.
- John Henry Effect — One group may view that it is competition with the other group and may work harder than than they would under normal circumstances. This generally is applied to the control group “taking on” the treatment group. The terms refers to the classic story of John Henry laying railroad track.
- Resentful Demoralization of the Control Group — The control group may become discouraged because it is not receiving the special attention that is given to the treatment group. They may perform lower than usual because of this.
- Regression ( Statistical Regression) — A class that scores particularly low can be expected to score slightly higher just by chance. Likewise, a class that scores particularly high, will have a tendency to score slightly lower by chance. The change in these scores may have nothing to do with the treatment.
- Implementation –The treatment may not be implemented as intended. A study where teachers are asked to use student modeling techniques may not show positive results, not because modeling techniques don’t work, but because the teacher didn’t implement them or didn’t implement them as they were designed.
- Compensatory Equalization of Treatmen t — Someone may feel sorry for the control group because they are not receiving much attention and give them special treatment. For example, a researcher could be studying the effect of laptop computers on students’ attitudes toward math. The teacher feels sorry for the class that doesn’t have computers and sponsors a popcorn party during math class. The control group begins to develop a more positive attitude about mathematics.
- Experimental Treatment Diffusion — Sometimes the control group actually implements the treatment. If two different techniques are being tested in two different third grades in the same building, the teachers may share what they are doing. Unconsciously, the control may use of the techniques she or he learned from the treatment teacher.
When planning a study, it is important to consider the threats to interval validity as we finalize the study design. After we complete our study, we should reconsider each of the threats to internal validity as we review our data and draw conclusions.
Del Siegle, Ph.D. Neag School of Education – University of Connecticut [email protected] www.delsiegle.com
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

Download Free PDF
Chapter 13 Experimental Research How to Design and Evaluate Research in Education 8th

In Part 4, we begin a more detailed discussion of some of the methodologies that educational researchers use. We concentrate here on quantitative research, with a separate chapter devoted to group-comparison experimental research, single-subject experimental research, correlational research, causal-comparative research, and survey research. In each chapter, we not only discuss the method in some detail, but we also provide examples of published studies in which the researchers used one of these methods. We conclude each chapter with an analysis of a particular study's strengths and weaknesses.
Related papers
European Journal of Education Studies, 2022
Educational research literature seems to highlight the use of different research methods, but there appear to be three main research strategies widely used and discussed. These are experiments, surveys and case studies. This paper concentrates on the experimental approach, which could be deemed for this paper to be of the “quantitative tradition”. The three strategies differ, then in two respects: (1) in how many cases are studied and, (2) in how these are selected. Strategies may be used to investigate any particular research topic, their strengths and weaknesses will have varying significance, depending on the purposes and circumstances of the research. The overall picture that emerges is that the experimental approach is based on multiple and varied sources of evidence and it must attend to process as well as to the outcome, it is better when it is theory-driven and it leads ultimately to multiple analyses that attempt to consolidate the program effect within some reasonable rang...
The experimental method is more exact compared to other quantitative methods, although it can have drawbacks, related to the positivist epistemological position. Determining exactly the educational effects of existing, innovative and new pedagogical concepts, programmes, systems, models, methods and instruments commands the use of experiments in pedagogical research. If completed pedagogical research projects are analysed, the conclusion is experiments are used much less frequently than other methods. This study determines the prevalence of parallel-group designs as compared to how frequently other experimental designs are used. A representative sample of scientific and professional papers was analysed and it was ascertained that the conducted experiments partly satisfy relevant theoretical and methodological criteria. It is evident that result reliability when using the experimental method is still relatively low, which may have negative effects on the development of pedagogical sciences and related scientific disciplines, as well as on scientifically grounded innovation of the teaching and learning process and enhancement of the educational process. Hence, it is crucial to use multi-method research approaches (employing the experimental method as appropriate, depending on the research problem) in preparing (and approving) doctoral dissertations, writing reviews and publishing research papers.
Journal of Computing in Higher Education, 2005
This course is an introduction to educational and social research for practitioners in schools and human services. The focus will be on fundamental issues in empirical research—that is research based on, concerned with, or verifiable by observation or experience, rather than theory or pure logic—including research methodology and research techniques (e.g., data collection, analysis and interpretation). This is not a research design or statistics course. In this course we will focus on: (a) developing an understanding of various kinds of educational and social research; (b) developing skills that will facilitate critical reading of educational and social research; and (c) exploring the role and use of research techniques to reflect upon and improve practice. The course includes “qualitative” and “quantitative” approaches to research. The terms “qualitative” and “quantitative” are commonly used to distinguish between experimental and non-experimental approaches, however, the difference between these “families” of research are more complex. Throughout the course we will explore the methodological as well as the technical differences between the two.
Un aspecto de fundamental importancia para la existencia de cualquier organismo socio–político es el problema de la legitimización del poder de los dirigentes de la entidad considerada. Si aceptamos que antes de la Conquista española el discurso legitimizador de los soberanos incas se basaba en la religión estatal del Tahuantinsuyu, quedan las siguientes preguntas: ¿qué modificaciones sufrió este discurso después de la llegada de los españoles? ¿Y qué estrategia adoptaron Manco Inca y sus sucesores para seguir siendo respetados y obedecidos por sus seguidores, después de retirarse al reducto de Vilcabamba?
TRIBUNA TERMAL, 45, 2024
Anuario Colombiano de Historia Social y de la Cultura, 2024
Nihon Shinri Gakkai Taikai happyo ronbunshu, 2014
Deutsche Zeitschrift für Philosophie , 2011
Schizophrenia Bulletin Open, 2020
ICCAD-2005. IEEE/ACM International Conference on Computer-Aided Design, 2005.
Revista de la Facultad de Derecho de México, 2017
Critical Review
Journal of Nepal Paediatric Society, 2014
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
10 Experimental research
Experimental research—often considered to be the ‘gold standard’ in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research—rather than for descriptive or exploratory research—where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalisability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments are conducted in field settings such as in a real organisation, and are high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favourably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receiving a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the ‘cause’ in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and ensures that each unit in the population has a positive chance of being selected into the sample. Random assignment, however, is a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group prior to treatment administration. Random selection is related to sampling, and is therefore more closely related to the external validity (generalisability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam.
Not conducting a pretest can help avoid this threat.
Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
Regression threat —also called a regression to the mean—refers to the statistical tendency of a group’s overall performance to regress toward the mean during a posttest rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest were possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-group experimental designs

Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest-posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement—especially if the pretest introduces unusual topics or content.
Posttest -only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

The treatment effect is measured simply as the difference in the posttest scores between the two groups:
![\[E = (O_{1} - O_{2})\,.\]](https://usq.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-90f2ce47275e7b35def5c5b52b7d7d45_l3.png "Rendered by QuickLaTeX.com")
The appropriate statistical analysis of this design is also a two-group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.

Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:
Due to the presence of covariates, the right statistical analysis of this design is a two-group analysis of covariance (ANCOVA). This design has all the advantages of posttest-only design, but with internal validity due to the controlling of covariates. Covariance designs can also be extended to pretest-posttest control group design.
Factorial designs
Two-group designs are inadequate if your research requires manipulation of two or more independent variables (treatments). In such cases, you would need four or higher-group designs. Such designs, quite popular in experimental research, are commonly called factorial designs. Each independent variable in this design is called a factor , and each subdivision of a factor is called a level . Factorial designs enable the researcher to examine not only the individual effect of each treatment on the dependent variables (called main effects), but also their joint effect (called interaction effects).

In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for three hours/week of instructional time than for one and a half hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid experimental designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomised bocks design, Solomon four-group design, and switched replications design.
Randomised block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full-time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between the treatment group (receiving the same treatment) and the control group (see Figure 10.5). The purpose of this design is to reduce the ‘noise’ or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.

Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs, but not in posttest-only designs. The design notation is shown in Figure 10.6.

Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organisational contexts where organisational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.

Quasi-experimental designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organisation is used as the treatment group, while another section of the same class or a different organisation in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impacted by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.

In addition, there are quite a few unique non-equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to the treatment or control group based on a cut-off score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardised test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program.

Because of the use of a cut-off score, it is possible that the observed results may be a function of the cut-off score rather than the treatment, which introduces a new threat to internal validity. However, using the cut-off score also ensures that limited or costly resources are distributed to people who need them the most, rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design do not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.

Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, say you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data is not available from the same subjects.

An interesting variation of the NEDV design is a pattern-matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique—based on the degree of correspondence between theoretical and observed patterns—is a powerful way of alleviating internal validity concerns in the original NEDV design.

Perils of experimental research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, often experimental research uses inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies, and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artefact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if in doubt, use tasks that are simple and familiar for the respondent sample rather than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Experimental Research
- First Online: 25 February 2021
Cite this chapter

- C. George Thomas 2
5513 Accesses
Experiments are part of the scientific method that helps to decide the fate of two or more competing hypotheses or explanations on a phenomenon. The term ‘experiment’ arises from Latin, Experiri, which means, ‘to try’. The knowledge accrues from experiments differs from other types of knowledge in that it is always shaped upon observation or experience. In other words, experiments generate empirical knowledge. In fact, the emphasis on experimentation in the sixteenth and seventeenth centuries for establishing causal relationships for various phenomena happening in nature heralded the resurgence of modern science from its roots in ancient philosophy spearheaded by great Greek philosophers such as Aristotle.
The strongest arguments prove nothing so long as the conclusions are not verified by experience. Experimental science is the queen of sciences and the goal of all speculation . Roger Bacon (1214–1294)
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Bibliography
Best, J.W. and Kahn, J.V. 1993. Research in Education (7th Ed., Indian Reprint, 2004). Prentice–Hall of India, New Delhi, 435p.
Google Scholar
Campbell, D. and Stanley, J. 1963. Experimental and quasi-experimental designs for research. In: Gage, N.L., Handbook of Research on Teaching. Rand McNally, Chicago, pp. 171–247.
Chandel, S.R.S. 1991. A Handbook of Agricultural Statistics. Achal Prakashan Mandir, Kanpur, 560p.
Cox, D.R. 1958. Planning of Experiments. John Wiley & Sons, New York, 308p.
Fathalla, M.F. and Fathalla, M.M.F. 2004. A Practical Guide for Health Researchers. WHO Regional Publications Eastern Mediterranean Series 30. World Health Organization Regional Office for the Eastern Mediterranean, Cairo, 232p.
Fowkes, F.G.R., and Fulton, P.M. 1991. Critical appraisal of published research: Introductory guidelines. Br. Med. J. 302: 1136–1140.
Gall, M.D., Borg, W.R., and Gall, J.P. 1996. Education Research: An Introduction (6th Ed.). Longman, New York, 788p.
Gomez, K.A. 1972. Techniques for Field Experiments with Rice. International Rice Research Institute, Manila, Philippines, 46p.
Gomez, K.A. and Gomez, A.A. 1984. Statistical Procedures for Agricultural Research (2nd Ed.). John Wiley & Sons, New York, 680p.
Hill, A.B. 1971. Principles of Medical Statistics (9th Ed.). Oxford University Press, New York, 390p.
Holmes, D., Moody, P., and Dine, D. 2010. Research Methods for the Bioscience (2nd Ed.). Oxford University Press, Oxford, 457p.
Kerlinger, F.N. 1986. Foundations of Behavioural Research (3rd Ed.). Holt, Rinehart and Winston, USA. 667p.
Kirk, R.E. 2012. Experimental Design: Procedures for the Behavioural Sciences (4th Ed.). Sage Publications, 1072p.
Kothari, C.R. 2004. Research Methodology: Methods and Techniques (2nd Ed.). New Age International, New Delhi, 401p.
Kumar, R. 2011. Research Methodology: A Step-by step Guide for Beginners (3rd Ed.). Sage Publications India, New Delhi, 415p.
Leedy, P.D. and Ormrod, J.L. 2010. Practical Research: Planning and Design (9th Ed.), Pearson Education, New Jersey, 360p.
Marder, M.P. 2011. Research Methods for Science. Cambridge University Press, 227p.
Panse, V.G. and Sukhatme, P.V. 1985. Statistical Methods for Agricultural Workers (4th Ed., revised: Sukhatme, P.V. and Amble, V. N.). ICAR, New Delhi, 359p.
Ross, S.M. and Morrison, G.R. 2004. Experimental research methods. In: Jonassen, D.H. (ed.), Handbook of Research for Educational Communications and Technology (2nd Ed.). Lawrence Erlbaum Associates, New Jersey, pp. 10211043.
Snedecor, G.W. and Cochran, W.G. 1980. Statistical Methods (7th Ed.). Iowa State University Press, Ames, Iowa, 507p.
Download references
Author information
Authors and affiliations.
Kerala Agricultural University, Thrissur, Kerala, India
C. George Thomas
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to C. George Thomas .
Rights and permissions
Reprints and permissions
Copyright information
© 2021 The Author(s)
About this chapter
Thomas, C.G. (2021). Experimental Research. In: Research Methodology and Scientific Writing . Springer, Cham. https://doi.org/10.1007/978-3-030-64865-7_5
Download citation
DOI : https://doi.org/10.1007/978-3-030-64865-7_5
Published : 25 February 2021
Publisher Name : Springer, Cham
Print ISBN : 978-3-030-64864-0
Online ISBN : 978-3-030-64865-7
eBook Packages : Education Education (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Chapter 10 Experimental Research
Experimental research, often considered to be the “gold standard” in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research (rather than for descriptive or exploratory research), where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalizability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments , conducted in field settings such as in a real organization, and high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic Concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favorably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receives a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the “cause” in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and assures that each unit in the population has a positive chance of being selected into the sample. Random assignment is however a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group, prior to treatment administration. Random selection is related to sampling, and is therefore, more closely related to the external validity (generalizability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
- History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
- Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
- Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam. Not conducting a pretest can help avoid this threat.
- Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
- Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
- Regression threat , also called a regression to the mean, refers to the statistical tendency of a group’s overall performance on a measure during a posttest to regress toward the mean of that measure rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest was possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-Group Experimental Designs
The simplest true experimental designs are two group designs involving one treatment group and one control group, and are ideally suited for testing the effects of a single independent variable that can be manipulated as a treatment. The two basic two-group designs are the pretest-posttest control group design and the posttest-only control group design, while variations may include covariance designs. These designs are often depicted using a standardized design notation, where R represents random assignment of subjects to groups, X represents the treatment administered to the treatment group, and O represents pretest or posttest observations of the dependent variable (with different subscripts to distinguish between pretest and posttest observations of treatment and control groups).
Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Figure 10.1. Pretest-posttest control group design
The effect E of the experimental treatment in the pretest posttest design is measured as the difference in the posttest and pretest scores between the treatment and control groups:
E = (O 2 – O 1 ) – (O 4 – O 3 )
Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement (especially if the pretest introduces unusual topics or content).
Posttest-only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

Figure 10.2. Posttest only control group design.
The treatment effect is measured simply as the difference in the posttest scores between the two groups:
E = (O 1 – O 2 )
The appropriate statistical analysis of this design is also a two- group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.
Covariance designs . Sometimes, measures of dependent variables may be influenced by extraneous variables called covariates . Covariates are those variables that are not of central interest to an experimental study, but should nevertheless be controlled in an experimental design in order to eliminate their potential effect on the dependent variable and therefore allow for a more accurate detection of the effects of the independent variables of interest. The experimental designs discussed earlier did not control for such covariates. A covariance design (also called a concomitant variable design) is a special type of pretest posttest control group design where the pretest measure is essentially a measurement of the covariates of interest rather than that of the dependent variables. The design notation is shown in Figure 10.3, where C represents the covariates:

Figure 10.3. Covariance design
Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:

Figure 10.4. 2 x 2 factorial design
Factorial designs can also be depicted using a design notation, such as that shown on the right panel of Figure 10.4. R represents random assignment of subjects to treatment groups, X represents the treatment groups themselves (the subscripts of X represents the level of each factor), and O represent observations of the dependent variable. Notice that the 2 x 2 factorial design will have four treatment groups, corresponding to the four combinations of the two levels of each factor. Correspondingly, the 2 x 3 design will have six treatment groups, and the 2 x 2 x 2 design will have eight treatment groups. As a rule of thumb, each cell in a factorial design should have a minimum sample size of 20 (this estimate is derived from Cohen’s power calculations based on medium effect sizes). So a 2 x 2 x 2 factorial design requires a minimum total sample size of 160 subjects, with at least 20 subjects in each cell. As you can see, the cost of data collection can increase substantially with more levels or factors in your factorial design. Sometimes, due to resource constraints, some cells in such factorial designs may not receive any treatment at all, which are called incomplete factorial designs . Such incomplete designs hurt our ability to draw inferences about the incomplete factors.
In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for 3 hours/week of instructional time than for 1.5 hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid Experimental Designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomized bocks design, Solomon four-group design, and switched replications design.
Randomized block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full -time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between treatment group (receiving the same treatment) or control group (see Figure 10.5). The purpose of this design is to reduce the “noise” or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.
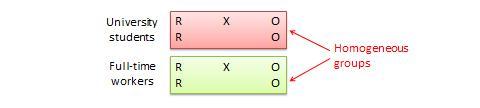
Figure 10.5. Randomized blocks design.
Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs but not in posttest only designs. The design notation is shown in Figure 10.6.

Figure 10.6. Solomon four-group design
Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organizational contexts where organizational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.
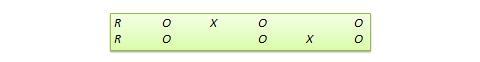
Figure 10.7. Switched replication design.
Quasi-Experimental Designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organization is used as the treatment group, while another section of the same class or a different organization in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of a certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impact by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.
Many true experimental designs can be converted to quasi-experimental designs by omitting random assignment. For instance, the quasi-equivalent version of pretest-posttest control group design is called nonequivalent groups design (NEGD), as shown in Figure 10.8, with random assignment R replaced by non-equivalent (non-random) assignment N . Likewise, the quasi -experimental version of switched replication design is called non-equivalent switched replication design (see Figure 10.9).

Figure 10.8. NEGD design.
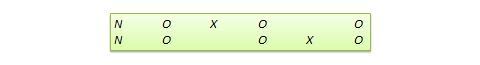
Figure 10.9. Non-equivalent switched replication design.
In addition, there are quite a few unique non -equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression-discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to treatment or control group based on a cutoff score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardized test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program. The design notation can be represented as follows, where C represents the cutoff score:
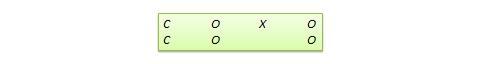
Figure 10.10. RD design.
Because of the use of a cutoff score, it is possible that the observed results may be a function of the cutoff score rather than the treatment, which introduces a new threat to internal validity. However, using the cutoff score also ensures that limited or costly resources are distributed to people who need them the most rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design does not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.
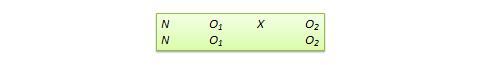
Figure 10.11. Proxy pretest design.
Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data are not available from the same subjects.

Figure 10.12. Separate pretest-posttest samples design.
Nonequivalent dependent variable (NEDV) design . This is a single-group pre-post quasi-experimental design with two outcome measures, where one measure is theoretically expected to be influenced by the treatment and the other measure is not. For instance, if you are designing a new calculus curriculum for high school students, this curriculum is likely to influence students’ posttest calculus scores but not algebra scores. However, the posttest algebra scores may still vary due to extraneous factors such as history or maturation. Hence, the pre-post algebra scores can be used as a control measure, while that of pre-post calculus can be treated as the treatment measure. The design notation, shown in Figure 10.13, indicates the single group by a single N , followed by pretest O 1 and posttest O 2 for calculus and algebra for the same group of students. This design is weak in internal validity, but its advantage lies in not having to use a separate control group.
An interesting variation of the NEDV design is a pattern matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique, based on the degree of correspondence between theoretical and observed patterns is a powerful way of alleviating internal validity concerns in the original NEDV design.
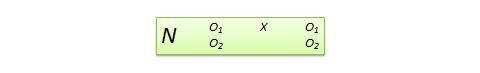
Figure 10.13. NEDV design.
Perils of Experimental Research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, many experimental research use inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artifact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if doubt, using tasks that are simpler and familiar for the respondent sample than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
- Social Science Research: Principles, Methods, and Practices. Authored by : Anol Bhattacherjee. Provided by : University of South Florida. Located at : http://scholarcommons.usf.edu/oa_textbooks/3/ . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
IMAGES
VIDEO
COMMENTS
a) assess the interactions between variables. b) assess the separate effect of each independent variable. c) study the combined effect of two or more variables. d) All of these answers are correct. D. A notable problem with experimental research in education is that: a) there is no way to control data collector bias.
The purpose of experimental research in education is to develop innovations that refers to the follow-. ing steps: substantiation, creation, approbation, verification, and implementation. Every ...
In educational research, the theory of change is usually articulated as participation in X intervention will result in Y outcome or change. This is a causal claim and is extremely difficult to conduct in educational settings. ... Wrong, because the problem with experimental design in education is we are dealing with real humans in the real ...
After we complete our study, we should reconsider each of the threats to internal validity as we review our data and draw conclusions. Del Siegle, Ph.D. Neag School of Education - University of Connecticut. [email protected]. The major feature that distinguishes experimental research from other types of research is that the researcher ...
Designing an Experiment. The most basic experimental design involves two groups: the experimental group and the control group. The two groups are designed to be the same except for one difference— experimental manipulation. The experimental group gets the experimental manipulation—that is, the treatment or variable being tested (in this ...
Research in educational contexts often employs quasi-experiments or natural experiments rather than true experiments, and these types of designs raise additional questions about the equivalence between experimental and control groups and the potential influence of confounding variables.
This is clearly a major issue in experimental research in science education. If researchers strongly expect co-operative learning, or a flipped classroom, or enquir y-based teaching (e .g., see ...
Highly significant are the most recent analyses of experiments funded by major national bodies. ... yet active placebos are seldom incorporated into experimental research designs in education. ... My point is that there has been an over-development in the sense of what an experiment might be in education. The problem has been that some ...
TRUE EXPERIMENTAL DESIGNS The essential ingredient of a true experimental design is that subjects are randomly assigned to treatment groups. As discussed earlier, random assignment is a powerful technique for controlling the subject characteristics threat to internal validity, a major consideration in educational research.
Current legislation requires educational practices be informed by science. The effort to establish educational practices supported by science has, to date, emphasized experiments with large numbers of participants who are randomly assigned to an intervention or control condition. A potential limitation of such an emphasis at the expense of other research methods is that evidence-based ...
10 Experimental research. 10. Experimental research. Experimental research—often considered to be the 'gold standard' in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different ...
Take your time with the planning process. "It's worth consulting other researchers, doing a pilot study to test it, before you go out spending the time, money, and energy to do the big study," Crawford says. "Because once you begin the study, you can't stop.". Challenge: Assembling a Research Team.
Licensed Under Creative Commons Attribution CC BY. 1. Educational Research: Educational Purposes, The Nature of Knowledge and Ethical Issues. Julio López-Alvarado. Association for the Promotion ...
Study with Quizlet and memorize flashcards containing terms like An important difference between experimental and non-experimental research is that the independent variable in experimental research is:, The feature that best characterizes experimental research is the:, The primary defect of the one-shot case study is: and more.
Experimental science is the queen of sciences and the goal of all speculation. Roger Bacon (1214-1294) Experiments are part of the scientific method that helps to decide the fate of two or more competing hypotheses or explanations on a phenomenon. The term 'experiment' arises from Latin, Experiri, which means, 'to try'.
the issues of professionalism, standards and accountability, addressed in the United States by the NAE's commission on the Improvement of Education Research, are of. central concern to colleagues in the UK. Schulman's piece sets the scene for the three essays which, each in their own way, challenge 'the intersection of the intellectual, the ...
Study with Quizlet and memorize flashcards containing terms like Experimental research is the most powerful research method for:, Why are control groups necessary in certain experiments?, To do an experimental study of the effects of TV viewing, a researcher must: and more. ... A major problem with experimental research in education is that:
Chapter 10 Experimental Research. Experimental research, often considered to be the "gold standard" in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels ...
A major problem with experimental research in education is that it is extremely hard to control every variable that could affect research results. Education is multifaceted and complex, and it is almost impossible to predict everything that could influence it. Further, there are many ethical considerations involved. In certain situations, it is ...
A major problem with experimental research in education is that: a. there is no way to control a "history" threat. b. there is no way to control the subject characteristics threat. c. the researcher may not have sufficient control over treatments. d. there is no way to control data collector bias.